Der Web-Scraping-Import funktioniert auf jeder öffentlichen Website, ohne API-Schlüssel oder Einrichtung. Er zeigt dir vor dem Festlegen immer eine Live-Vorschau eines extrahierten Produkts, damit du zuerst bestätigen kannst, dass die Daten korrekt aussehen.
So funktioniert es
1
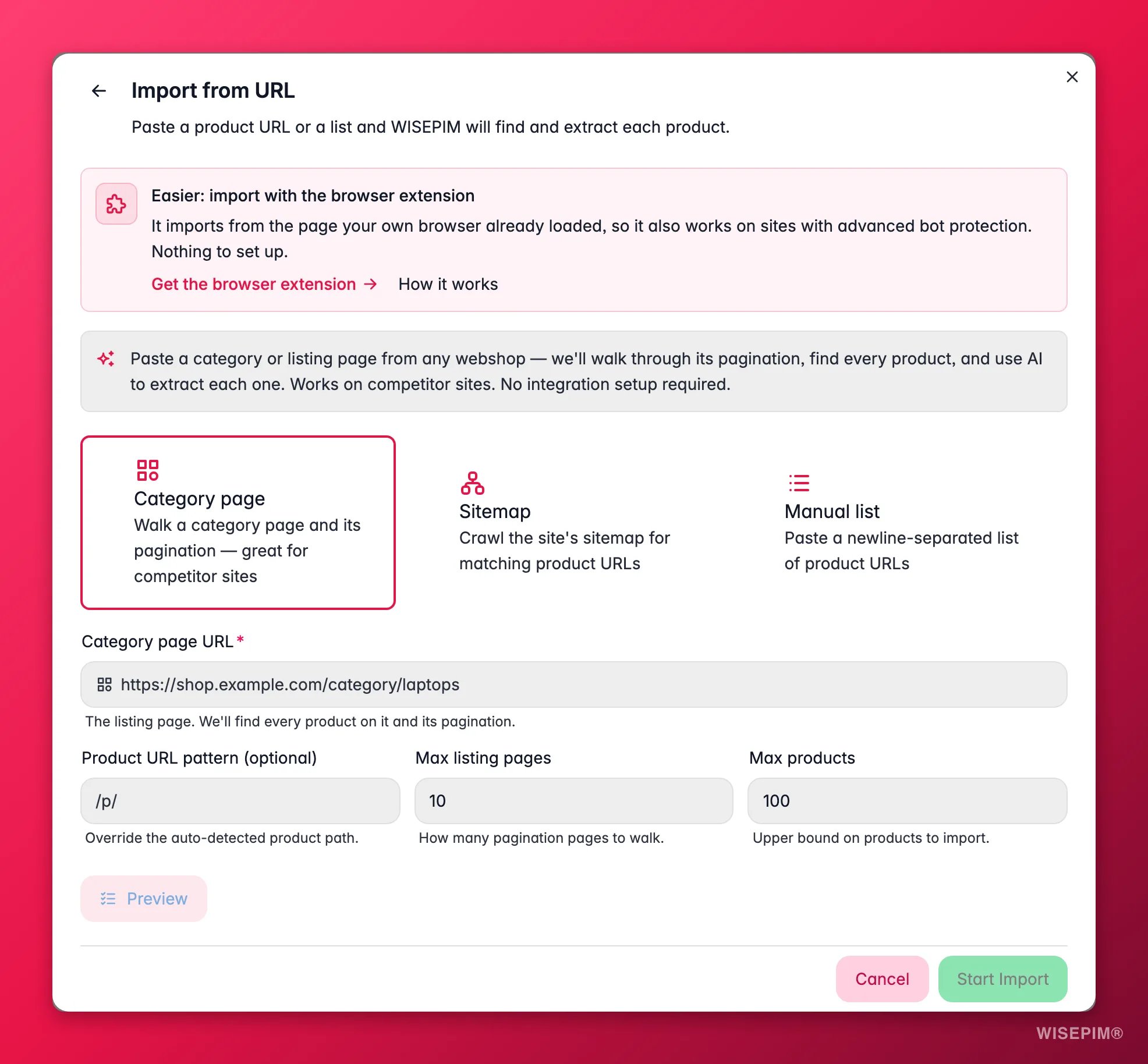
Wähle einen Quellmodus
Kategorieseite durchläuft eine Listenseite und ihre Seitennummerierung, um jedes Produkt zu finden (am besten für den Katalog eines Lieferanten oder Mitbewerbers). Sitemap startet von einer Produkt-URL und findet ähnliche Seiten auf der gesamten Website. Manuelle Liste nimmt eine Liste von Produkt-URLs, die du einfügst, eine pro Zeile.
2
Füge die URL und Begrenzungen hinzu
Füge die Start-URL ein. Lege optional ein URL-Muster fest (um nur die richtigen Seiten einzubeziehen) sowie Obergrenzen dafür, wie viele Listenseiten und Produkte abgerufen werden, damit ein erster Durchlauf klein bleibt.
3
Sieh dir ein Produkt in der Vorschau an
Starte die Vorschau. WISEPIM meldet, wie viele Produkt-URLs es gefunden hat, das erkannte Muster, einige Beispiel-URLs und ein vollständig extrahiertes Produkt, sodass du prüfen kannst, ob die Felder korrekt übernommen wurden.
4
Importieren
Zufrieden mit der Vorschau? Starte den Import. Er läuft im Hintergrund, sodass du die Seite verlassen und den Fortschritt im Process Tracker verfolgen kannst. Wenn er fertig ist, sind die Produkte in deinem Katalog und einsatzbereit.
Einstellungen, die du festlegen kannst
Du gestaltest jeden Scrape mit ein paar optionalen Überschreibungen. Die Standardwerte funktionieren für die meisten Websites, greife also nur dann zu diesen, wenn ein Durchlauf einen Anstoß braucht:- Sitemap-URL überschreiben: Verweise WISEPIM auf die richtige Sitemap, wenn eine Website keine in ihrer
robots.txtangibt. Nutze dies, wenn der Sitemap-Modus die Produkt-URLs nicht von selbst finden kann. - Produkt-URL-Muster überschreiben: Sage WISEPIM, welche URLs als Produkte gelten (zum Beispiel
/p/oder/products/), wenn das automatisch erkannte Muster die falschen Seiten erfasst. - Max. Listenseiten: wie viele Seitennummerierungs-Seiten einer Kategorie durchlaufen werden. Erhöhe den Wert für große Kataloge, halte ihn für einen schnellen Test niedrig.
- Max. Produkte: eine Obergrenze dafür, wie viele Produkte ein Durchlauf importiert. Eine Sicherheitsgrenze, die einen ersten Durchlauf klein und vorhersehbar hält.
Ein einzelner Durchlauf kann bis zu 5.000 Produkt-URLs finden. Von jeder Seite werden bis zu 1.000.000 Zeichen HTML gelesen, und ein Durchlauf liest über alle Seiten hinweg bis zu 8.000.000 Zeichen. Diese Obergrenzen reichen für die meisten Lieferantenkataloge großzügig aus. Wenn du etwas Größeres abrufst, teile es nach Kategorie in mehrere Durchläufe auf.
Die Vorschau lesen
Die Vorschau gibt es, damit du nie blind importierst:- Anzahl der gefundenen URLs zeigt dir, ob der Crawl ungefähr die erwartete Produktanzahl gefunden hat. Null oder viel zu wenige bedeutet, dass das Muster oder die Start-URL angepasst werden muss.
- Das erkannte Muster zeigt, welche URLs als Produkte behandelt werden. Wenn es Kategorie- oder Blog-Seiten erfasst, schränke das Muster mit der Überschreibung des Produkt-URL-Musters ein.
- Das extrahierte Beispiel ist der eigentliche Test: Prüfe, dass Name, Preis, Bilder und wichtige Attribute korrekt zugeordnet wurden, bevor du dich auf den vollständigen Durchlauf festlegst.
Wenn eine Website den Scraper blockiert
Manche Webshops sitzen hinter einem Bot-Schutz: Cloudflare, DataDome und ähnliche Dienste, die alles blockieren, was kein echter Mensch in einem echten Browser ist. Wenn WISEPIM auf einen davon trifft, scheitert es nicht mit einer vagen Fehlermeldung. Es sagt dir, welche Website geschützt ist und welcher Dienst blockiert, und weist dich dann auf die Lösung hin. Die Lösung ist die WISEPIM-Browser-Erweiterung. Sie importiert von der Seite, die dein eigener Browser bereits geladen hat, sodass der Schutz nie greift: Aus Sicht der Website bist du einfach ein Besucher, der eine Produktseite liest. Du bekommst dieselbe Extraktion, auf Websites, die der Crawler nicht erreichen kann.Mit der Browser-Erweiterung importieren
Die Erweiterung funktioniert in Chrome, Edge und Firefox. Die Einrichtung dauert eine Minute:1
Die Erweiterung installieren
Öffne die Seite der Browser-Erweiterung in WISEPIM und wähle Zu Chrome hinzufügen, Zu Edge hinzufügen oder Zu Firefox hinzufügen.
2
Das Projekt wählen
Wähle zurück in WISEPIM unter In Projekt importieren das Projekt, in das dieser Browser importieren soll.
3
Diesen Browser verbinden
Klicke auf Diesen Browser verbinden. Der Browser erscheint nun in deiner Liste Verbundene Browser und zeigt, in welches Projekt er importiert und wann er zuletzt genutzt wurde.
4
Von jeder Produktseite importieren
Öffne eine Produktseite in diesem Browser und nutze die Erweiterung, um sie an WISEPIM zu senden.
Jeder verbundene Browser bekommt einen eigenen Schlüssel, begrenzt auf das eine Projekt, das du gewählt hast. Die Erweiterung sieht nie dein Passwort. Klicke bei einem Browser auf Trennen, und er importiert sofort nicht mehr.
Gescrapte Produkte automatisch klassifizieren
Wenn dein Projekt Klassifizierungsstandards übernommen hat, können sich gescrapte Importe selbst darin einsortieren. Bevor irgendetwas anderes läuft, wird jedes importierte Produkt mit den Standards abgeglichen, die du übernommen hast. Konfiguriere das unter Einstellungen → Scraping-Import, im Abschnitt Klassifikation:- Familien aus ETIM zuweisen (standardmäßig an): ein Produkt, das zu einer deiner übernommenen ETIM-Klassen passt, erhält im Moment seiner Ankunft die Familie dieser Klasse - mit allen ihren Attributen.
- Kategorien mit GS1 GPC abgleichen (standardmäßig an): gescrapte Breadcrumbs landen in deinen übernommenen GPC-Kategorien, statt daneben einen doppelten Baum anzulegen.
- Fehlende Klassen beim Import übernehmen (standardmäßig aus): passt ein Produkt eindeutig zu einer Klasse oder Kategorie, die du noch nicht übernommen hast, wird sie direkt übernommen. Lass es aus, um nur zu nutzen, was du bereits übernommen hast.
Gescrapte Produkte automatisch anreichern
Eine gescrapte Produktseite trägt selten alles, was du willst. WISEPIM kann diese Lücke in dem Moment schließen, in dem ein Import fertig ist, ohne dass du etwas auswählst.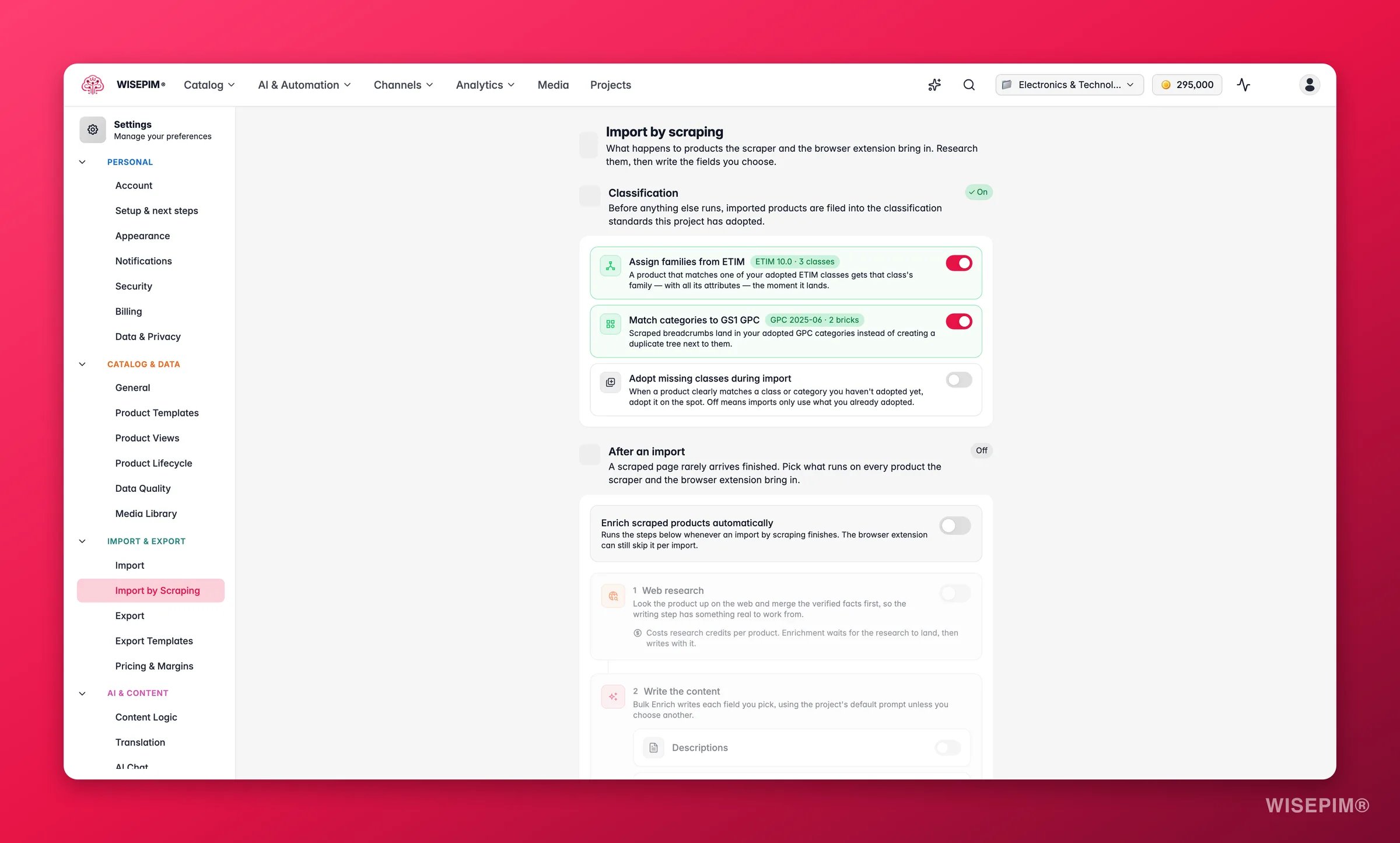
- Web-Recherche sammelt Fakten über jedes Produkt aus dem Web. Dieser Schritt benötigt den Pro-Plan oder höher. Ohne ihn kannst du die Web-Recherche weiterhin von Hand aus der Produkttabelle starten.
- Bulk-Anreicherung schreibt die Felder, die du wählst: Beschreibungen, Kurzbeschreibungen, Titel, SEO-Titel und Meta sowie Attribute. Jedes Feld nutzt den Standardprompt deines Projekts, sofern du keinen anderen wählst.
Handle nach deinen Erkenntnissen
Die Vorschau hat 0 (oder viel zu wenige) Produkte gefunden
Die Vorschau hat 0 (oder viel zu wenige) Produkte gefunden
Die Start-URL oder das Muster stimmt nicht. Bei einer Kategorieseite vergewissere dich, dass du die Listenseite eingefügt hast (nicht ein einzelnes Produkt); im Sitemap-Modus füge eine echte Produkt-URL ein, damit WISEPIM das Muster lernen kann. Passe die Muster-Überschreibung an und mach erneut eine Vorschau. Ergebnis: Der Crawl findet das vollständige Sortiment, bevor du einen Importlauf dafür aufwendest.
Beim Beispielprodukt fehlen Felder
Beim Beispielprodukt fehlen Felder
Manche Websites verstecken Daten in Skripten oder Bildern. Mach erneut eine Vorschau, um zu bestätigen, dass es durchgängig ist, importiere, was sauber extrahiert wird, und fülle dann die Lücken mit Produkte anreichern (die AI kann die Produktbilder lesen, um Attribute wiederherzustellen). Ergebnis: ein vollständiger Katalog, selbst wenn die Quellseite dünn war.
Du wirst erneut von derselben Website importieren
Du wirst erneut von derselben Website importieren
Notiere dir die Einstellungen, die funktioniert haben: den Quellmodus, die Start- oder Kategorie-URL und alle Muster- oder Sitemap-Überschreibungen. Wenn der Lieferant das nächste Mal aktualisiert, gib dieselben Werte ein, um die Änderungen abzurufen. Für Quellen, die du häufig erneut importierst, ist ein strukturierter Feed die zuverlässigere Langzeitoption, sofern einer verfügbar ist. Ergebnis: wiederholbares Lieferanten-Onboarding.
Du brauchst einen Feed, keinen Scrape
Du brauchst einen Feed, keinen Scrape
Wenn die Quelle dir einen XML- oder CSV-Feed bereitstellen kann, bevorzuge den Feed-Hub-Import oder den Dateiimport: Strukturierte Feeds sind schneller und zuverlässiger als das Crawlen. Nutze das Scraping, wenn kein Feed verfügbar ist. Ergebnis: das richtige Werkzeug für jede Quelle.
Der Vergleich
Verwandte Themen
Produkte importieren
Dateibasierter Import (CSV, Excel), wenn du strukturierte Daten hast.
Feed Hub
Aus XML-/Feed-Quellen importieren und in sie veröffentlichen.
Web-Recherche
Recherchiere Produkte im Web, um das anzureichern, was du bereits hast.
Produkte anreichern
Fülle die Lücken, die der Scrape hinterlassen hat, mit AI.