La importación por web scraping funciona en cualquier sitio web público, sin claves de API ni configuración. Siempre te muestra una vista previa en vivo de un producto extraído antes de confirmar, para que primero compruebes que los datos tienen buen aspecto.
Cómo funciona
1
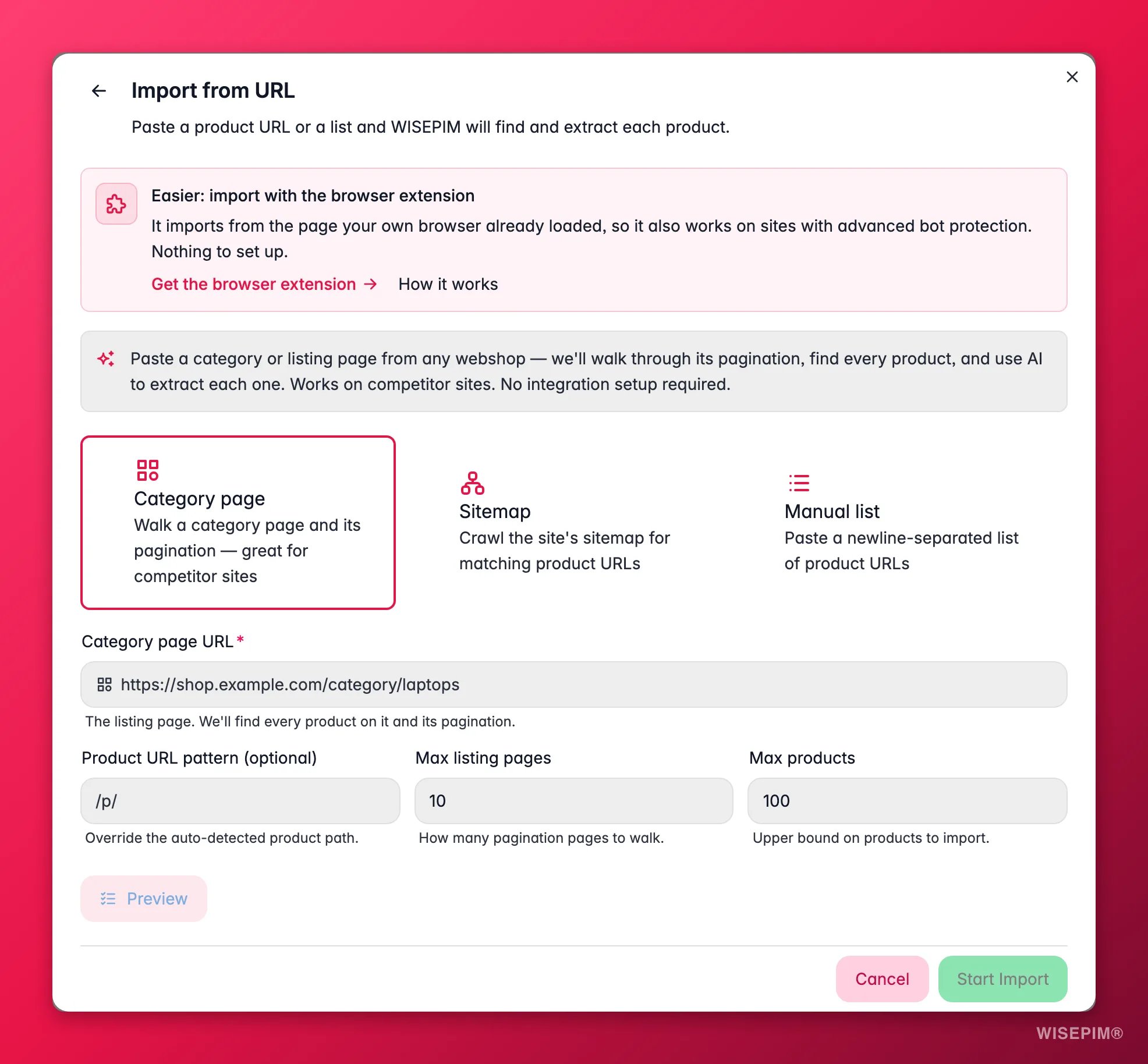
Elige un modo de origen
Página de categoría recorre una página de listado y su paginación para encontrar todos los productos (lo mejor para el catálogo de un proveedor o de la competencia). Sitemap parte de una URL de producto y encuentra páginas similares por todo el sitio. Lista manual toma una lista de URL de producto que pegas, una por línea.
2
Añade la URL y los límites
Pega la URL de inicio. Si quieres, define un patrón de URL (para incluir solo las páginas adecuadas) y topes de cuántas páginas de listado y productos extraer, para que una primera ejecución se mantenga pequeña.
3
Previsualiza un producto
Ejecuta la vista previa. WISEPIM informa de cuántas URL de producto coincidieron, el patrón que detectó, unas cuantas URL de ejemplo y un producto extraído por completo para que compruebes que los campos llegaron correctamente.
4
Importar
¿Conforme con la vista previa? Inicia la importación. Se ejecuta en segundo plano, así que puedes dejar la página y seguir el progreso en el Seguimiento de procesos. Cuando termina, los productos están en tu catálogo, listos para trabajar con ellos.
Controles que puedes definir
Das forma a cada scraping con unos cuantos ajustes opcionales. Los valores por defecto funcionan en la mayoría de sitios, así que recurre a estos solo cuando una ejecución necesite un empujón:- Sustituir la URL del sitemap: apunta WISEPIM al sitemap correcto cuando un sitio no lo declara en su
robots.txt. Úsalo si el modo sitemap no puede encontrar las URL de producto por sí solo. - Sustituir el patrón de URL de producto: indica a WISEPIM qué URL cuentan como productos (por ejemplo
/p/o/products/) cuando el patrón detectado automáticamente recoge las páginas equivocadas. - Máximo de páginas de listado: cuántas páginas de paginación de una categoría recorrer. Súbelo para catálogos grandes, mantenlo bajo para una prueba rápida.
- Máximo de productos: un límite superior de cuántos productos importa una ejecución. Un tope de seguridad que mantiene una primera ejecución pequeña y predecible.
Una sola ejecución puede coincidir con hasta 5.000 URL de producto. De cada página se leen hasta 1.000.000 de caracteres de HTML, y una ejecución lee hasta 8.000.000 de caracteres en total entre todas las páginas. Estos techos son suficientes para la mayoría de catálogos de proveedor. Si vas a extraer algo más grande, divídelo en varias ejecuciones por categoría.
Cómo leer la vista previa
La vista previa existe para que nunca importes a ciegas:- El número de URL coincidentes te dice si el rastreo encontró aproximadamente el número de productos que esperabas. Cero o demasiado pocos significa que hay que ajustar el patrón o la URL de inicio.
- El patrón detectado muestra qué URL se tratarán como productos. Si está recogiendo páginas de categoría o de blog, afina el patrón con la opción para sustituir el patrón de URL de producto.
- La muestra extraída es la prueba de verdad: comprueba que el nombre, el precio, las imágenes y los atributos clave se mapearon correctamente antes de comprometerte con la ejecución completa.
Cuando un sitio bloquea el scraper
Algunas tiendas online están detrás de protección antibots: Cloudflare, DataDome y servicios similares que bloquean todo lo que no sea una persona real en un navegador real. Cuando WISEPIM se topa con uno, no falla con un error vago. Te dice qué sitio está protegido y qué servicio está bloqueando, y te señala la solución. La solución es la extensión de navegador de WISEPIM. Importa desde la página que tu propio navegador ya cargó, así que la protección no se aplica: para el sitio, no eres más que un visitante leyendo una página de producto. Obtienes la misma extracción, en sitios a los que el rastreador no puede llegar.Importar con la extensión de navegador
La extensión funciona en Chrome, Edge y Firefox. Configurarla lleva un minuto:1
Instala la extensión
Abre la página de la extensión de navegador en WISEPIM y elige Añadir a Chrome, Añadir a Edge o Añadir a Firefox.
2
Elige el proyecto
De vuelta en WISEPIM, elige el proyecto al que debe importar este navegador en Importar al proyecto.
3
Conecta este navegador
Haz clic en Conectar este navegador. El navegador aparece ahora en tu lista de Navegadores conectados, mostrando a qué proyecto importa y cuándo se usó por última vez.
4
Importa desde cualquier página de producto
Abre una página de producto en ese navegador y usa la extensión para enviarla a WISEPIM.
Cada navegador conectado obtiene su propia clave, limitada al único proyecto que elegiste. La extensión nunca ve tu contraseña. Haz clic en Desconectar en un navegador y deja de importar de inmediato.
Clasificar automáticamente los productos extraídos
Si tu proyecto ha adoptado estándares de clasificación, las importaciones por scraping pueden archivarse solas en ellos. Antes de que se ejecute cualquier otra cosa, cada producto importado se comprueba contra los estándares que has adoptado. Configúralo en Ajustes → Importar por scraping, en la sección Clasificación:- Asignar familias desde ETIM (activado por defecto): un producto que coincide con una de tus clases ETIM adoptadas recibe la familia de esa clase - con todos sus atributos, en el momento en que aterriza.
- Vincular categorías a GS1 GPC (activado por defecto): las migas de pan scrapeadas aterrizan en tus categorías GPC adoptadas en lugar de crear un árbol duplicado al lado.
- Adoptar clases faltantes durante la importación (desactivado por defecto): cuando un producto coincide claramente con una clase o categoría que aún no has adoptado, se adopta en el momento. Déjalo desactivado para usar solo lo que ya adoptaste.
Enriquecer automáticamente los productos extraídos
Una página de producto extraída rara vez trae todo lo que quieres. WISEPIM puede cerrar ese hueco en cuanto termina una importación, sin que selecciones nada.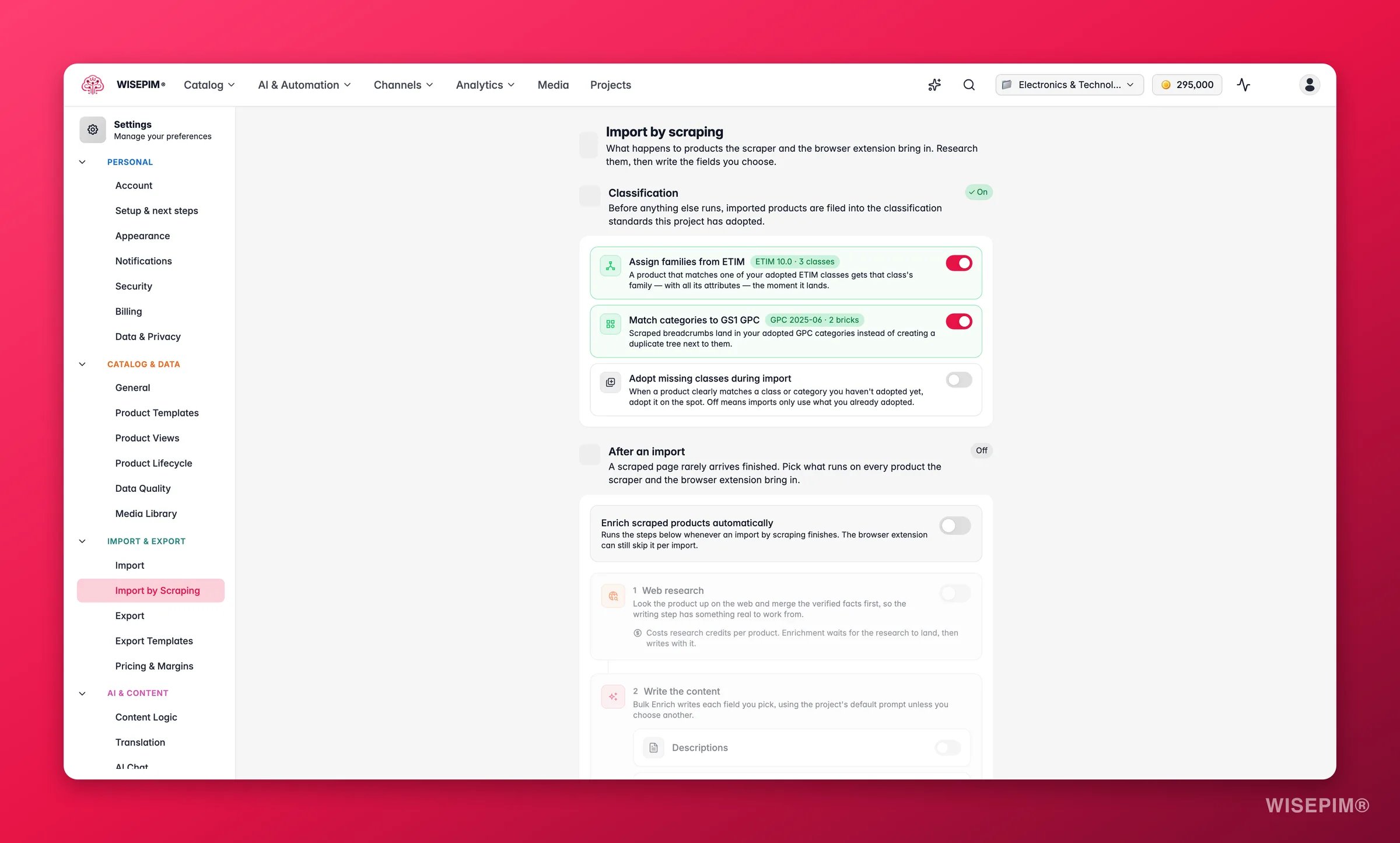
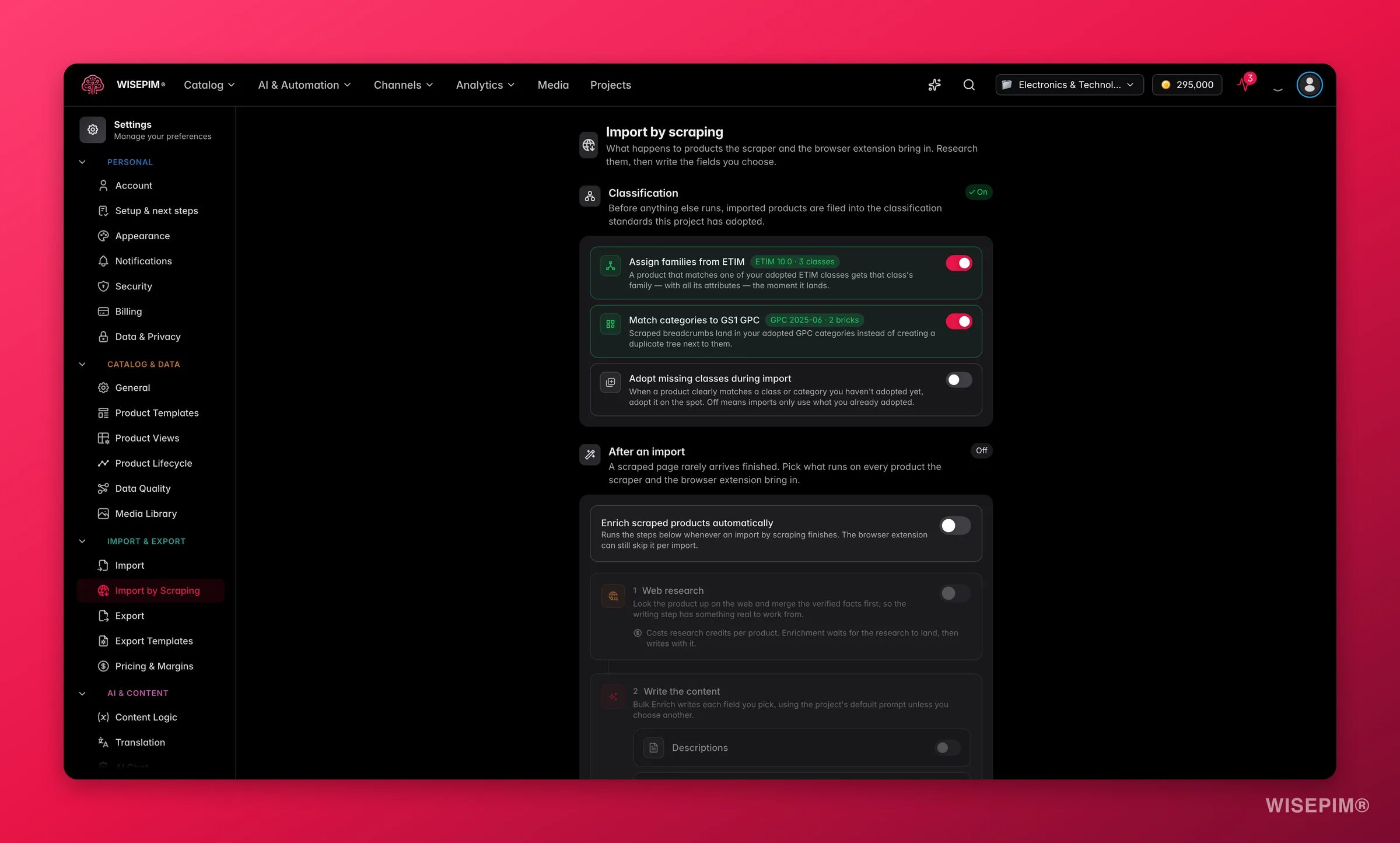
- La investigación web reúne datos sobre cada producto desde la web. Este paso requiere el plan Pro o superior. Sin él, aún puedes ejecutar la investigación web a mano desde la tabla de productos.
- El Enriquecimiento masivo escribe los campos que elijas: descripciones, descripciones cortas, títulos, título y meta SEO, y atributos. Cada campo usa el prompt predeterminado de tu proyecto salvo que elijas otro.
Actúa según lo que encuentres
La vista previa coincidió con 0 (o demasiado pocos) productos
La vista previa coincidió con 0 (o demasiado pocos) productos
La URL de inicio o el patrón no son correctos. Para una página de categoría, asegúrate de haber pegado la página de listado (no un solo producto); para el modo sitemap, pega una URL de producto real para que WISEPIM pueda aprender el patrón. Ajusta la sustitución del patrón y previsualiza de nuevo. Resultado: el rastreo encuentra el conjunto completo antes de gastar una ejecución de importación en él.
Al producto de muestra le faltan campos
Al producto de muestra le faltan campos
Algunos sitios esconden datos en scripts o imágenes. Vuelve a previsualizar para confirmar que es consistente, importa lo que se extrae limpiamente y luego rellena los huecos con Enriquecer productos (la AI puede leer las imágenes del producto para recuperar atributos). Resultado: un catálogo completo incluso cuando la página de origen tenía poca información.
Vas a importar del mismo sitio otra vez
Vas a importar del mismo sitio otra vez
Anota los ajustes que funcionaron: el modo de origen, la URL de inicio o de categoría, y cualquier sustitución de patrón o de sitemap. La próxima vez que el proveedor actualice, introduce los mismos valores para traer los cambios. Para fuentes que reimportas a menudo, un feed estructurado es la opción más fiable a largo plazo cuando hay uno disponible. Resultado: incorporación de proveedores repetible.
Necesitas un feed, no un scraping
Necesitas un feed, no un scraping
Si la fuente puede darte un feed XML o CSV, es mejor usar la importación de Feed Hub o la importación de archivos: los feeds estructurados son más rápidos y fiables que el rastreo. Usa el scraping cuando no haya un feed disponible. Resultado: la herramienta adecuada para cada fuente.
Cómo se compara
Relacionado
Importar productos
Importación basada en archivos (CSV, Excel) cuando tienes datos estructurados.
Feed Hub
Importa desde y publica en fuentes XML / feed.
Investigación web
Investiga productos en la web para enriquecer lo que ya tienes.
Enriquecer productos
Rellena con AI los huecos que dejó el scraping.