Web scraping-import werkt op elke openbare website, zonder API-sleutels of setup. Het toont je altijd een live voorbeeld van één geëxtraheerd product voordat je je vastlegt, zodat je eerst kunt bevestigen dat de data er goed uitziet.
Hoe het werkt
1
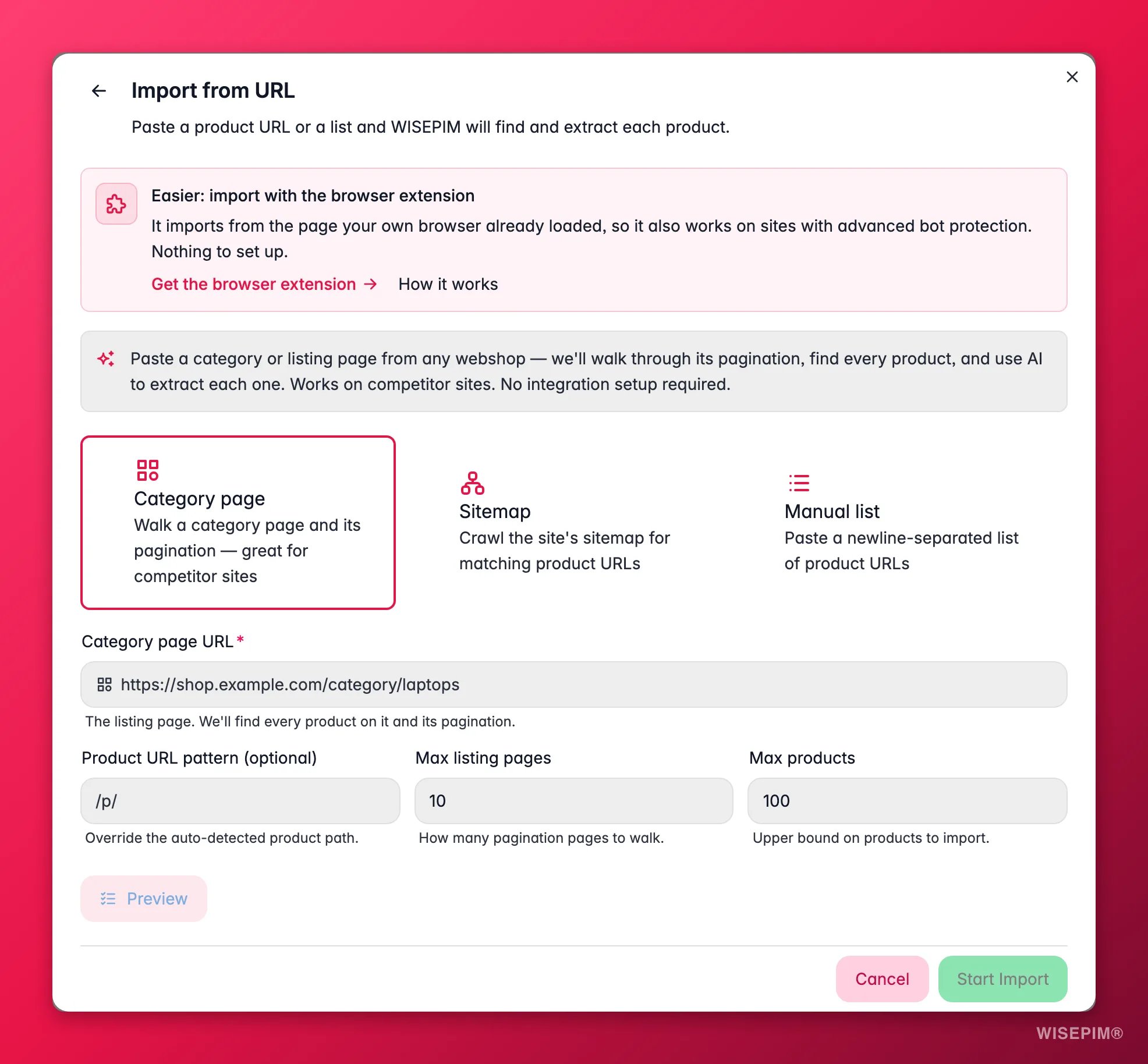
Kies een bronmodus
Categoriepagina doorloopt een overzichtspagina en de paginering om elk product te vinden (het beste voor de catalogus van een leverancier of concurrent). Sitemap begint bij één product-URL en vindt vergelijkbare pagina’s op de site. Handmatige lijst gebruikt een lijst met product-URL’s die je erin plakt, één per regel.
2
Voeg de URL en limieten toe
Plak de start-URL. Stel desgewenst een URL-patroon in (om alleen de juiste pagina’s mee te nemen) en limieten voor hoeveel overzichtspagina’s en producten worden opgehaald, zodat een eerste run klein blijft.
3
Bekijk één product als voorbeeld
Voer het voorbeeld uit. WISEPIM rapporteert hoeveel product-URL’s hij heeft gevonden, het patroon dat hij detecteerde, een paar voorbeeld-URL’s en één volledig geëxtraheerd product, zodat je kunt controleren of de velden goed zijn overgekomen.
4
Importeren
Tevreden met het voorbeeld? Start de import. Die draait op de achtergrond, dus je kunt de pagina verlaten en de voortgang volgen in de Process Tracker. Zodra het klaar is, staan de producten in je catalogus, klaar om mee te werken.
Instellingen die je kunt aanpassen
Je stuurt elke scrape met een paar optionele overrides. De standaardinstellingen werken voor de meeste sites, dus gebruik deze alleen wanneer een run een zetje nodig heeft:- Sitemap-URL override: wijs WISEPIM naar de juiste sitemap wanneer een site er geen aangeeft in zijn
robots.txt. Gebruik dit als de sitemap-modus zelf geen product-URL’s kan vinden. - Override voor product-URL-patroon: vertel WISEPIM welke URL’s als producten tellen (bijvoorbeeld
/p/of/products/) wanneer het automatisch gedetecteerde patroon de verkeerde pagina’s oppikt. - Max overzichtspagina’s: hoeveel pagineringspagina’s van een categorie worden doorlopen. Verhoog dit voor grote catalogi, houd het laag voor een snelle test.
- Max producten: een bovengrens voor hoeveel producten een run importeert. Een veiligheidslimiet die een eerste run klein en voorspelbaar houdt.
Eén run kan tot 5.000 product-URL’s matchen. Per pagina wordt tot 1.000.000 tekens HTML gelezen, en een run leest in totaal tot 8.000.000 tekens over alle pagina’s. Deze plafonds zijn ruim genoeg voor de meeste leverancierscatalogi. Haal je iets groters op, splits het dan per categorie op in meerdere runs.
Het voorbeeld lezen
Het voorbeeld bestaat zodat je nooit blind importeert:- Aantal gevonden URL’s vertelt je of de crawl ongeveer het aantal producten heeft gevonden dat je verwachtte. Nul of veel te weinig betekent dat het patroon of de start-URL moet worden aangepast.
- Het gedetecteerde patroon toont welke URL’s als producten worden behandeld. Pikt het categorie- of blogpagina’s op? Scherp het patroon dan aan met de override voor het product-URL-patroon.
- Het geëxtraheerde voorbeeld is de echte test: controleer of naam, prijs, afbeeldingen en belangrijke attributen correct zijn overgekomen voordat je je aan de volledige run vastlegt.
Wanneer een site de scraper blokkeert
Sommige webshops zitten achter botbescherming: Cloudflare, DataDome en vergelijkbare diensten die alles blokkeren wat geen echt persoon in een echte browser is. Loopt WISEPIM daartegenaan, dan faalt het niet met een vage foutmelding. Het vertelt je welke site beschermd is en welke dienst blokkeert, en wijst je daarna op de oplossing. De oplossing is de WISEPIM-browserextensie. Die importeert vanaf de pagina die je eigen browser al heeft geladen, waardoor de bescherming nooit van toepassing is: voor de site ben je gewoon een bezoeker die een productpagina leest. Je krijgt dezelfde extractie, op sites die de crawler niet kan bereiken.Importeren met de browserextensie
De extensie werkt op Chrome, Edge en Firefox. De installatie kost een minuut:1
Installeer de extensie
Open de browserextensiepagina in WISEPIM en kies Toevoegen aan Chrome, Toevoegen aan Edge of Toevoegen aan Firefox.
2
Kies het project
Kies terug in WISEPIM onder Importeren in project het project waarin deze browser moet importeren.
3
Verbind deze browser
Klik op Deze browser verbinden. De browser verschijnt nu in je lijst Verbonden browsers, met daarbij in welk project hij importeert en wanneer hij voor het laatst is gebruikt.
4
Importeer vanaf elke productpagina
Open een productpagina in die browser en gebruik de extensie om hem naar WISEPIM te sturen.
Elke verbonden browser krijgt een eigen sleutel, beperkt tot het ene project dat je koos. De extensie ziet je wachtwoord nooit. Klik op Verbinding verbreken bij een browser en hij stopt direct met importeren.
Classificeer gescrapete producten automatisch
Heeft je project classificatiestandaarden overgenomen, dan kunnen gescrapete imports zichzelf daarin indelen. Voordat er iets anders draait, wordt elk geïmporteerd product getoetst aan de standaarden die je hebt overgenomen. Stel dit in onder Instellingen → Importeren via scraping, in de sectie Classificatie:- Families toewijzen vanuit ETIM (standaard aan): een product dat overeenkomt met een van je overgenomen ETIM-klassen krijgt de familie van die klasse - met alle attributen - op het moment dat het binnenkomt.
- Categorieën koppelen aan GS1 GPC (standaard aan): gescrapete kruimelpaden landen in je overgenomen GPC-categorieën in plaats van een dubbele boom ernaast te maken.
- Ontbrekende klassen overnemen tijdens import (standaard uit): wanneer een product duidelijk overeenkomt met een klasse of categorie die je nog niet hebt overgenomen, wordt die ter plekke overgenomen. Laat het uit om alleen te gebruiken wat je al hebt overgenomen.
Gescrapete producten automatisch verrijken
Een gescrapete productpagina bevat zelden alles wat je wilt. WISEPIM kan dat gat dichten zodra een import klaar is, zonder dat je iets hoeft te selecteren.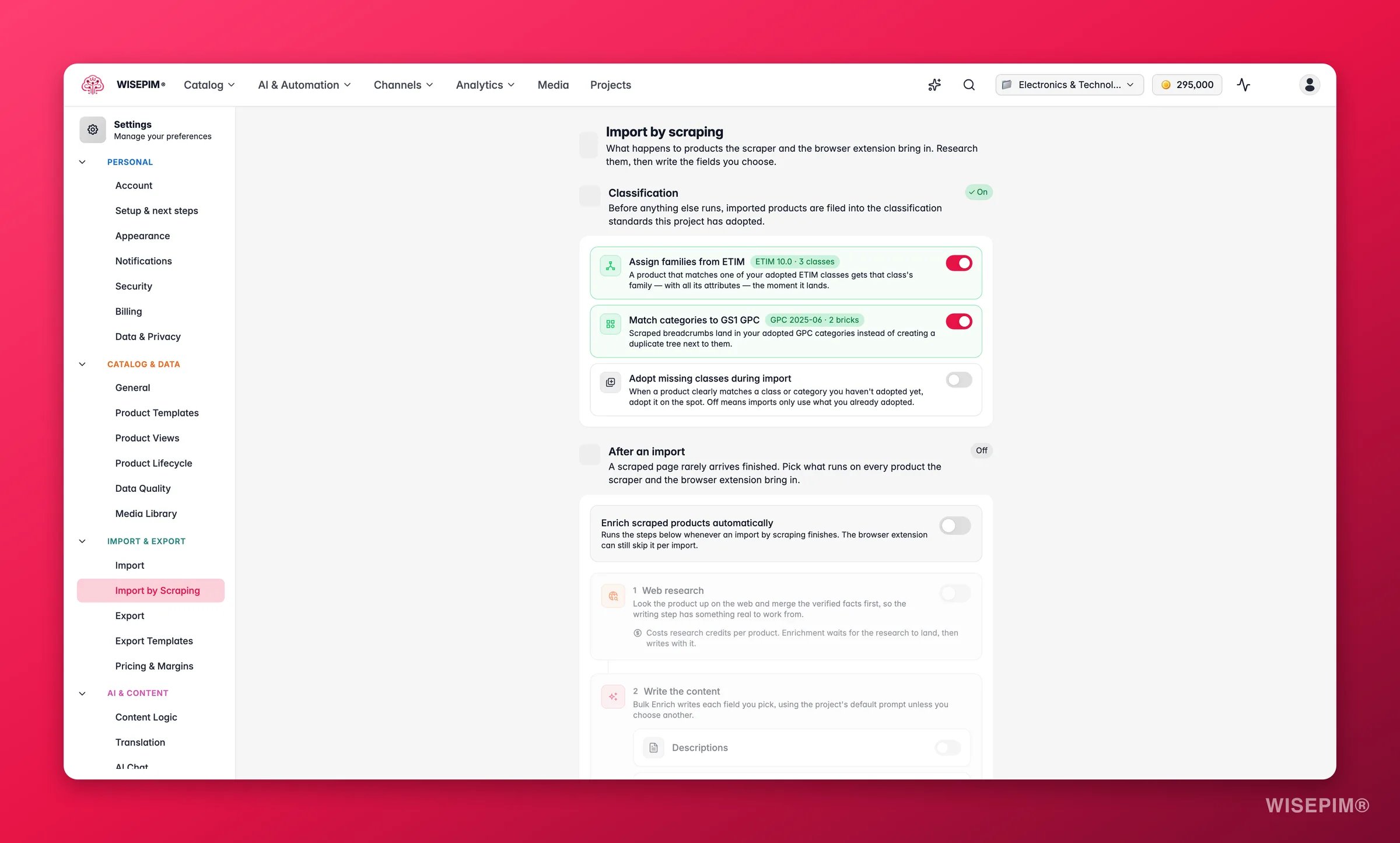
- Webonderzoek verzamelt feiten over elk product van het web. Deze stap vereist het Pro-plan of hoger. Zonder dat plan kun je webonderzoek nog steeds handmatig uitvoeren vanuit de productentabel.
- Bulk verrijken schrijft de velden die je kiest: beschrijvingen, korte beschrijvingen, titels, SEO-titel en meta, en attributen. Elk veld gebruikt de standaardprompt van je project, tenzij je een andere kiest.
Doe iets met wat je vindt
Het voorbeeld vond 0 (of veel te weinig) producten
Het voorbeeld vond 0 (of veel te weinig) producten
De start-URL of het patroon klopt niet. Zorg bij een categoriepagina dat je de overzichtspagina hebt geplakt (niet één enkel product); plak bij de sitemap-modus een echte product-URL zodat WISEPIM het patroon kan leren. Pas de patroon-override aan en bekijk opnieuw een voorbeeld. Resultaat: de crawl vindt de volledige set voordat je er een importrun aan besteedt.
Bij het voorbeeldproduct ontbreken velden
Bij het voorbeeldproduct ontbreken velden
Sommige sites verstoppen data in scripts of afbeeldingen. Bekijk opnieuw een voorbeeld om te bevestigen dat het consistent is, importeer wat netjes wordt geëxtraheerd, en vul daarna de hiaten op met Producten verrijken (AI kan de productafbeeldingen lezen om attributen terug te halen). Resultaat: een volledige catalogus, zelfs wanneer de bronpagina mager was.
Je gaat opnieuw importeren vanaf dezelfde site
Je gaat opnieuw importeren vanaf dezelfde site
Noteer de instellingen die werkten: de bronmodus, de start- of categorie-URL en eventuele patroon- of sitemap-overrides. De volgende keer dat de leverancier bijwerkt, vul je dezelfde waarden in om de wijzigingen op te halen. Voor bronnen die je vaak opnieuw importeert, is een gestructureerde feed de betrouwbaardere langetermijnoptie wanneer die beschikbaar is. Resultaat: herhaalbare leveranciers-onboarding.
Je hebt een feed nodig, geen scrape
Je hebt een feed nodig, geen scrape
Kan de bron je een XML- of CSV-feed geven? Kies dan liever Feed Hub-import of bestandsimport: gestructureerde feeds zijn sneller en betrouwbaarder dan crawlen. Gebruik scraping wanneer er geen feed beschikbaar is. Resultaat: het juiste gereedschap voor elke bron.
Hoe het zich verhoudt
Gerelateerd
Producten importeren
Bestandsgebaseerde import (CSV, Excel) wanneer je gestructureerde data hebt.
Feed Hub
Importeer vanuit en publiceer naar XML- / feed-bronnen.
Web research
Onderzoek producten op het web om aan te vullen wat je al hebt.
Producten verrijken
Vul met AI de hiaten die de scrape achterliet.