Die Databricks-Integration ist nur im Enterprise-Plan verfügbar. Kontaktiere unser Vertriebsteam, um mehr über Enterprise-Funktionen und Preise zu erfahren.
Bevor du startest
- Ein WISEPIM-Konto im Enterprise-Plan
- Einen Databricks-Workspace mit aktiviertem Unity Catalog
- Berechtigung zum Erstellen von Schemas und Tabellen in deinem Databricks-Katalog
- Deinen Databricks Server Hostname, HTTP Path und eine Authentifizierungsmethode (Personal Access Token oder OAuth)
Verbindungsdetails aus Databricks holen
Sammle vier Dinge aus deinem Databricks-Workspace, bevor du die Integration einrichtest.Server Hostname und HTTP Path kopieren
Gehe zu SQL Warehouses (oder Compute für Cluster):
- Wähle das SQL Warehouse oder den Cluster aus, mit dem sich WISEPIM verbindet.
- Klicke auf Connection Details.
- Kopiere den Server Hostname, etwa
adb-1234567890.1.azuredatabricks.net. - Kopiere den HTTP Path, etwa
/sql/1.0/warehouses/abc123def456.
Authentifizierung einrichten
Wähle eine von zwei Methoden.Option A: Personal Access Token
- Klicke oben rechts auf deinen Benutzernamen.
- Gehe zu Settings, dann Developer, dann Access Tokens.
- Klicke auf Generate New Token, gib eine Beschreibung wie
WISEPIM Integrationein und lege ein Ablaufdatum fest. - Kopiere das Token jetzt. Databricks zeigt es nicht erneut an.
- Erstelle in deiner Databricks-Kontokonsole einen Service Principal.
- Generiere dafür eine Client ID und ein Client Secret.
- Gewähre ihm Zugriff auf den Workspace und den Zielkatalog.
Databricks mit WISEPIM verbinden
Mit deinen Details bereit richtest du die Integration in WISEPIM ein.Integration öffnen
Melde dich bei WISEPIM an und gehe zur Seite Integrationen. Suche die Kachel Databricks im App Marketplace und klicke darauf.
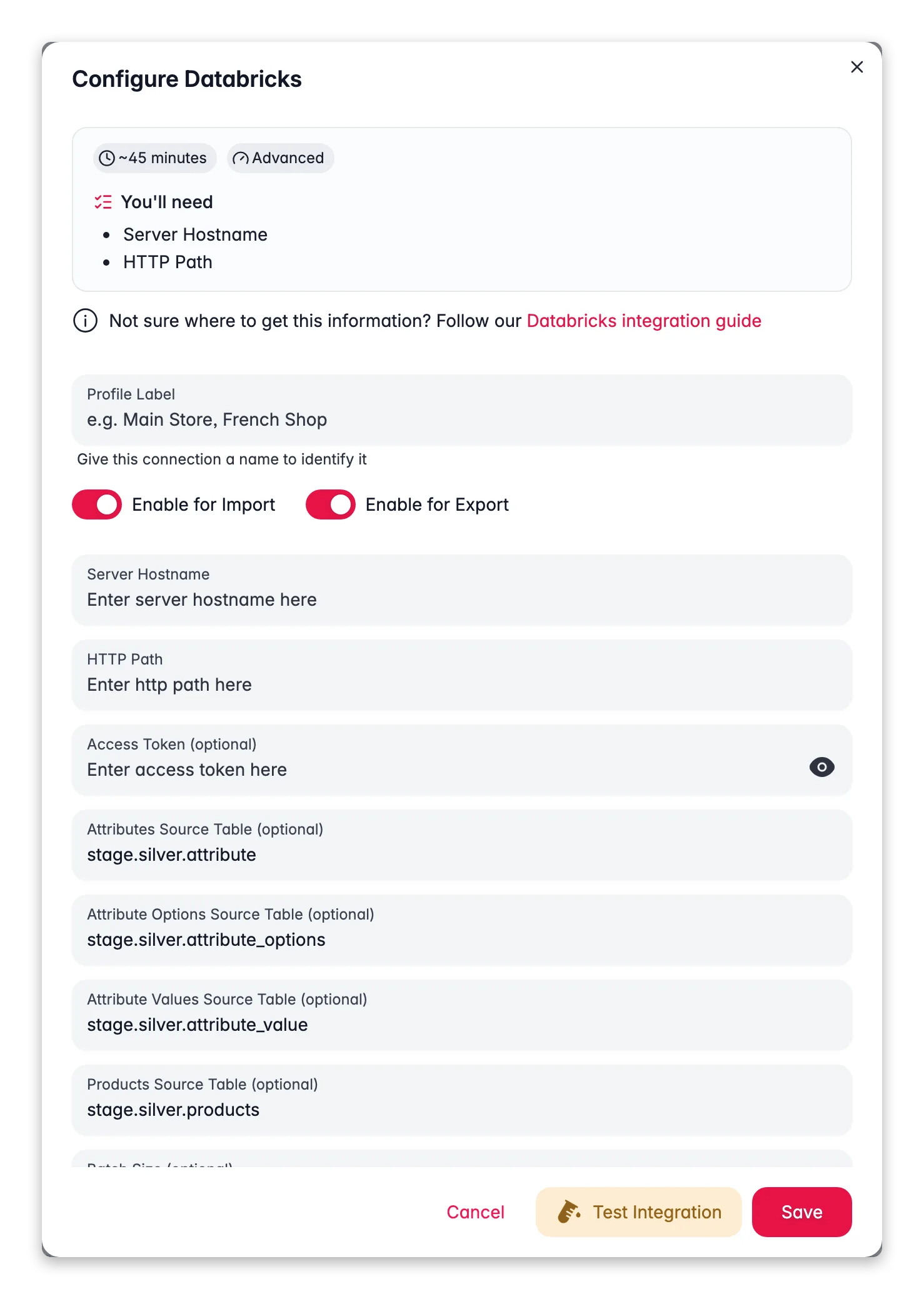
Verbindungsdetails eingeben
Fülle die Felder aus:Verbindungseinstellungen
- Server Hostname: der Hostname deines Databricks-Workspace
- HTTP Path: der Pfad zu deinem SQL Warehouse oder Cluster
- Access Token: dein Personal Access Token
- Oder Client ID und Client Secret: deine OAuth-Service-Principal-Zugangsdaten
- Catalog: dein Unity Catalog-Name, etwa
wisepim_data - Schema: dein Schema-Name innerhalb des Catalogs, etwa
product_catalog
Quelltabellen hinzufügen (optional)
Nur nötig, wenn du Daten aus Databricks nach WISEPIM importierst:
- Attributes Source Table: die Tabelle mit den Attributdefinitionen
- Attribute Options Source Table: die Tabelle mit den Attributoptionswerten
- Products Source Table: die Tabelle mit den Produktdaten
- Batch Size: pro Batch verarbeitete Zeilen (Standard
1000)
Verbindung testen
Klicke auf Verbindung testen, um zu bestätigen, dass WISEPIM deinen Workspace sowie den gewählten Catalog und das Schema erreichen kann.
Produktdaten nach Databricks exportieren
Übertrage angereicherte Produkte aus WISEPIM nach Delta Lake für Analysen und ML.
WISEPIM exportiert:
- Produktkennungen (IDs, SKUs, EAN/GTIN)
- Produktnamen und Beschreibungen (alle Sprachen)
- Preise und Lagerinformationen
- Kategoriehierarchien
- Produktattribute und benutzerdefinierte Felder
- Bild-URLs und Metadaten
- Übersetzungsstatus und Qualitätsbewertungen
Produktdaten aus Databricks importieren
Liegen deine Produktdaten in Databricks, etwa aus vorgelagerten Pipelines, hole sie nach WISEPIM.Halte deine Quelltabellen auf einem konsistenten Schema. WISEPIM ordnet Spalten automatisch den Produktattributen zu, und du kannst die Zuordnung über den Attribut-Mapper anpassen.
Batch-Größe für große Kataloge anpassen
WISEPIM verarbeitet Daten in Batches. Passe die Batch-Größe an deinen Katalog an, um Geschwindigkeit und Ressourcennutzung auszubalancieren.| Katalog-Größe | Produkte | Empfohlene Batch-Größe |
|---|---|---|
| Klein | Unter 10.000 | 1000 (Standard) |
| Mittel | 10.000 bis 100.000 | 5000 |
| Groß | 100.000+ | 10000, und behalte die Ressourcennutzung im Blick |
Was du mit deinen Daten bauen kannst
Sobald deine Produkte in Databricks sind, kannst du sie für Analysen und Data Science nutzen.Produktleistungs-Analysen
Produktleistungs-Analysen
- Erstelle Dashboards, um die Produktleistung über Kanäle und Märkte zu verfolgen.
- Finde heraus, welche Attribute mit höheren Konversionsraten korrelieren.
- Vergleiche die Leistung über Sprachen und Regionen.
Machine-Learning-Pipelines
Machine-Learning-Pipelines
- Trainiere Produktempfehlungsmodelle mit angereicherten Daten.
- Erstelle Nachfrageprognosen aus historischen Produkt- und Preisdaten.
- Entwickle Preisoptimierung auf Basis von Marktdaten.
- Nutze WISEPIM-Produkt-Embeddings für Ähnlichkeitssuche und Clustering.
Data Governance
Data Governance
- Verfolge die Datenherkunft von der Quelle über die Anreicherung bis zum Export mit Unity Catalog.
- Richte Zugriffskontrollen ein, wer Produktdaten lesen und ändern darf.
- Überwache jede Änderung mit dem Transaktionsprotokoll von Delta Lake.
Fehlerbehebung
Verbindungsfehler
Verbindungsfehler
- Prüfe, ob der Server Hostname korrekt ist und die vollständige Domain enthält, etwa
adb-1234567890.1.azuredatabricks.net. - Prüfe, ob der HTTP Path auf ein aktives SQL Warehouse oder einen aktiven Cluster verweist.
- Stelle sicher, dass das Warehouse oder der Cluster läuft, nicht gestoppt oder beendet.
- Bei einem Personal Access Token: prüfe, ob es nicht abgelaufen ist.
- Bei OAuth: bestätige, dass der Service Principal Zugriff auf Workspace-Ebene hat.
Authentifizierungsprobleme
Authentifizierungsprobleme
- Generiere dein Access Token neu, wenn du vermutest, dass es abgelaufen oder kompromittiert ist.
- Prüfe bei OAuth, ob Client ID und Client Secret korrekt sind.
- Stelle sicher, dass der Benutzer oder Service Principal
USE CATALOGundUSE SCHEMAfür den Ziel-Catalog und das Ziel-Schema hat.
Exportprobleme
Exportprobleme
- Bestätige, dass der Benutzer
CREATE TABLEundMODIFYfür das Ziel-Schema hat. - Prüfe, ob die Catalog- und Schema-Namen korrekt geschrieben sind und im Unity Catalog existieren.
- Sind Exporte langsam? Reduziere die Batch-Größe oder nutze ein größeres SQL Warehouse.
- Sieh im Fehlerprotokoll von WISEPIM nach Meldungen der Databricks-API.
Importprobleme
Importprobleme
- Prüfe, ob die Quelltabellennamen korrekt sind und die Tabellen existieren.
- Bestätige, dass der Benutzer
SELECTfür die Quelltabellen hat. - Prüfe, ob die Schemas der Quelltabellen zum erwarteten Format von WISEPIM passen.
- Laufen Importe in eine Zeitüberschreitung? Reduziere die Batch-Größe.
Verwandte Themen
Produkte importieren
Hole Produkte aus deinen Databricks-Tabellen.
Produkte anreichern
Verbessere Produktinhalte mit AI.
Produkte exportieren
Sende Produkte an Delta Lake-Tabellen.